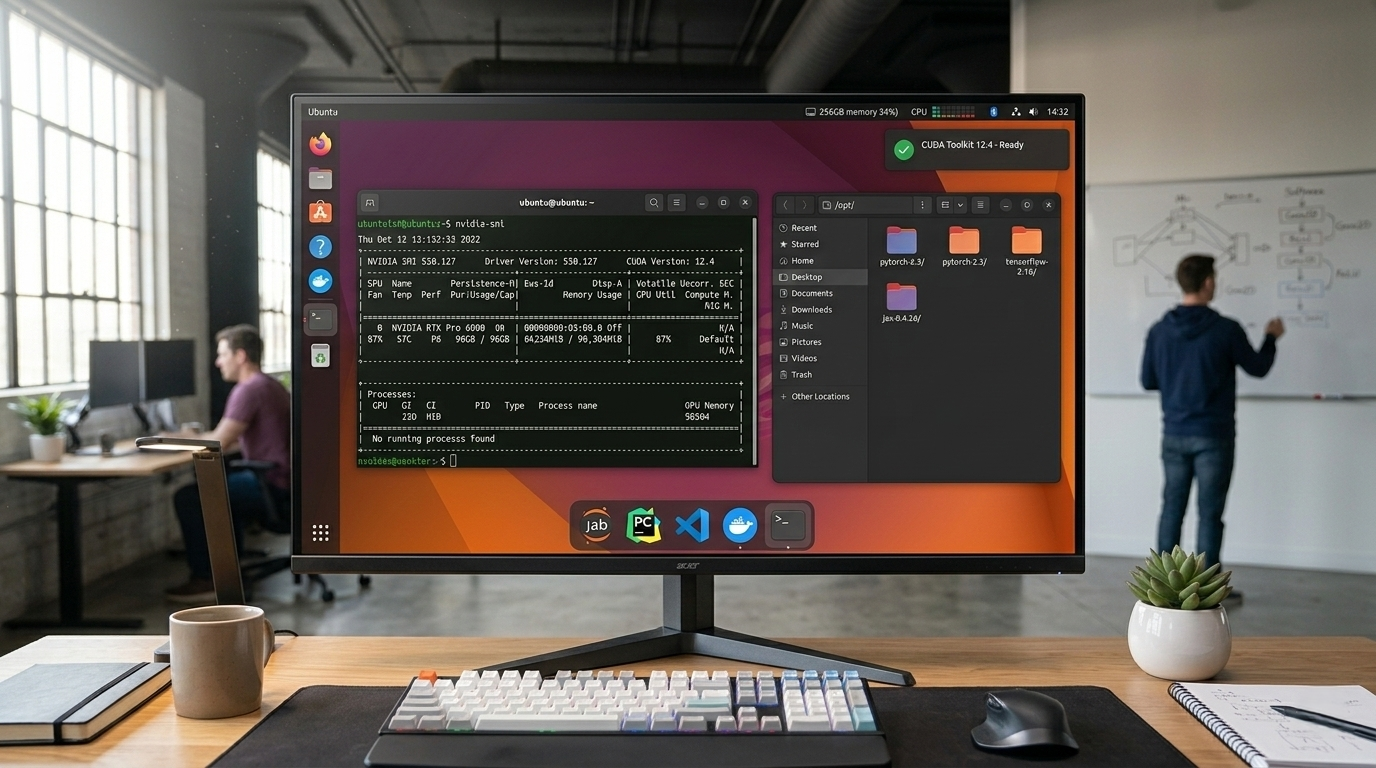




Setting up an AI development environment in 2026 remains one of the most frustrating bottlenecks for machine learning engineers, data scientists, and AI researchers. A fresh Ubuntu installation requires hours of work: downloading CUDA toolkit versions that match your GPU driver, ensuring cuDNN libraries are compatible with your chosen deep learning framework, resolving Python dependency conflicts, and debugging obscure installation errors that documentation never quite explains. For teams trying to move from concept to training runs quickly, these setup delays translate directly into lost productivity and delayed projects. ABS AI Workstations eliminate this friction entirely by shipping with validated, production-ready software stacks that work immediately upon first boot.
Pre-Configured Environments: From Unboxing to Training in Minutes
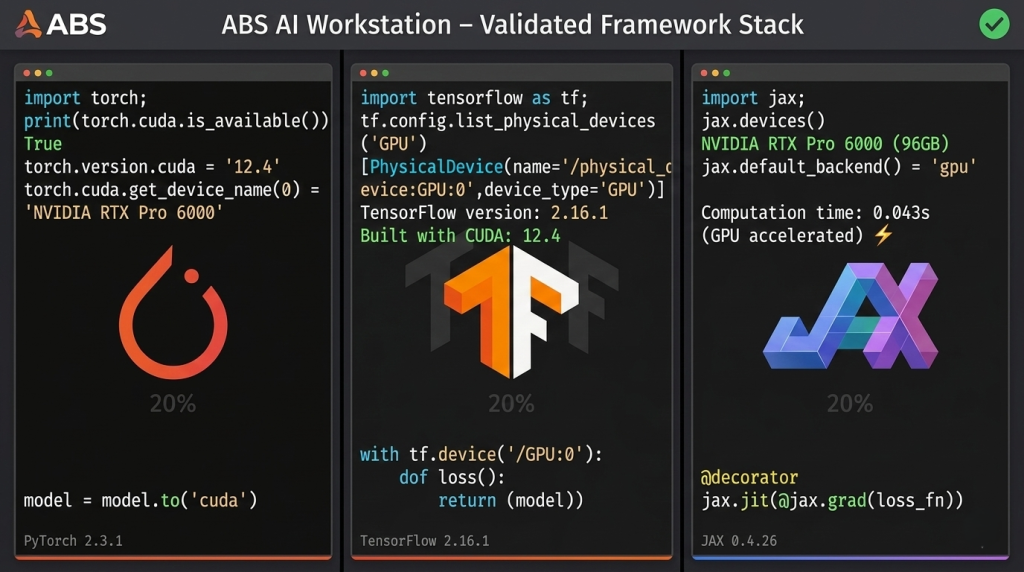
Unlike consumer desktops or generic workstations that ship with basic operating systems, ABS AI Workstations arrive with complete AI development environments pre-installed and tested. Every system includes Ubuntu 22.04 LTS or newer, configured specifically for deep learning workloads with kernel optimizations for GPU compute. NVIDIA’s CUDA 12.4 toolkit and cuDNN 8.9 libraries come pre-installed with drivers certified for RTX Professional GPUs, eliminating the version mismatch problems that plague custom installations.
The integration extends beyond system software. PyTorch 2.3 and TensorFlow 2.16 are pre-installed with GPU acceleration enabled and validated on the exact hardware configuration in your chassis. JAX 0.4.26, increasingly popular for research applications requiring automatic differentiation and XLA compilation, is ready to use with proper GPU backend configuration. This level of integration means you can clone your model repository, create a virtual environment, install project-specific dependencies, and begin training within thirty minutes of unboxing the workstation.
For users who prefer containerized workflows, Docker and NVIDIA Container Runtime are configured and tested, allowing you to pull pre-built deep learning containers from NVIDIA NGC or build custom images without wrestling with GPU passthrough configuration. The ABS Zaurion Aqua comes configured for this exact use case, with sufficient system resources to run multiple isolated container environments concurrently.
Framework Compatibility: Tested Configurations You Can Trust
The AI software ecosystem evolves rapidly, with framework updates arriving monthly and new tools emerging constantly. Maintaining compatibility across CUDA versions, Python releases, and deep learning frameworks requires dedicated testing that individual developers rarely have time to perform. ABS validates every software combination on each workstation configuration before shipping, ensuring that critical workflows function reliably.
This validation matters most for multi-GPU training scenarios. PyTorch’s Distributed Data Parallel (DDP) and TensorFlow’s tf.distribute strategies rely on precise driver configurations and inter-GPU communication libraries. The ABS Zaurion Duo Aqua ships with verified NCCL (NVIDIA Collective Communications Library) configuration for its dual RTX Pro 6000 GPUs, enabling near-linear scaling for training workloads without debugging communication bottlenecks.
Driver stability represents another critical advantage. NVIDIA’s professional GPU drivers follow a different release cadence than GeForce drivers, prioritizing stability and long-term support over cutting-edge gaming features. ABS systems use production-branch drivers tested with specific framework versions, reducing the risk of training failures caused by driver bugs or incompatibilities. When new framework versions arrive, ABS tests compatibility and provides validated upgrade paths, maintaining system stability while allowing users to adopt new capabilities.
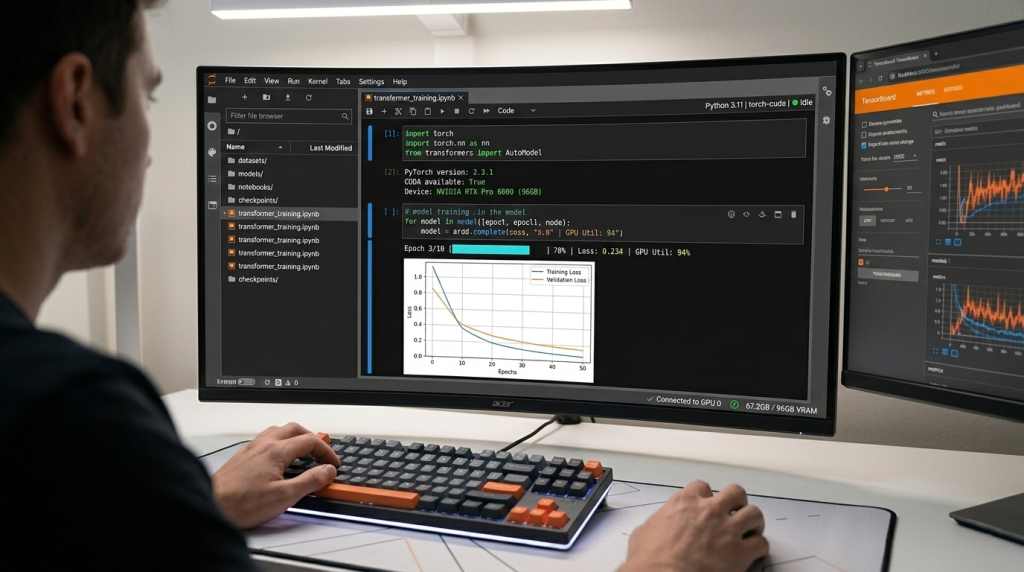 Jupyter and Development Tools: Interactive AI Workflows
Jupyter and Development Tools: Interactive AI Workflows
Modern AI development relies heavily on interactive experimentation through Jupyter notebooks and integrated development environments. ABS workstations include JupyterLab 4.0 pre-configured with GPU access, allowing data scientists to prototype models, visualize training metrics, and document experiments in a familiar web-based interface. Extensions for PyTorch and TensorFlow profiling come pre-installed, providing immediate access to GPU utilization metrics and training bottleneck analysis.
For users preferring traditional IDEs, popular options like Visual Studio Code, PyCharm Professional, and Spyder are tested for compatibility with the installed AI stack. Remote development over SSH works reliably, allowing teams to provision shared workstations that multiple researchers access remotely while leveraging local GPU resources. This configuration is particularly valuable for academic labs and small research teams who need to maximize hardware utilization across multiple projects.
Data science workflow tools round out the software ecosystem. Git and Git LFS (Large File Storage) handle version control for code and model checkpoints. MLflow and Weights & Biases clients enable experiment tracking and model registry workflows. DVC (Data Version Control) integrates with high-performance NVMe storage for dataset versioning. These tools arrive pre-installed and configured, reducing the setup overhead that typically delays new projects.
Cloud Alternative: Local Development Without Recurring Costs
Cloud platforms like AWS, Google Cloud, and Azure offer GPU instances for AI training, but the developer experience differs significantly from local workstations. Cloud workflows require uploading datasets, configuring security credentials, managing instance lifecycles, and monitoring egress costs. For development iterations where you train a model, review results, adjust hyperparameters, and retrain dozens of times, cloud latency and workflow friction add up quickly.
ABS AI Workstations provide immediate access to GPU resources without upload delays or API limits. You can experiment freely without per-hour cost anxiety, knowing that your workstation is always ready. For organizations working with proprietary or sensitive data, local compute ensures data never leaves your network, simplifying compliance and reducing security concerns. The software integration advantages amplify these benefits: your development environment remains consistent across projects rather than varying between cloud instance types with different driver versions and framework configurations.
The cost comparison becomes particularly compelling for teams who develop continuously rather than training occasionally. A high-utilization development pattern—running training jobs, inference benchmarks, and data preprocessing for eight hours daily—costs approximately $12,000 annually on major cloud platforms for equivalent RTX Pro 6000 GPU access. The ABS Zaurion Ruby pays for itself within the first year while providing superior development experience and eliminating ongoing per-hour charges.
Framework Updates: Staying Current Without Breaking Production
The AI research community moves quickly. PyTorch 3.0 introduced compiled mode with torch.compile() for 2x inference speedups. TensorFlow 2.16 added native mixed-precision training improvements. JAX 0.4 delivered better automatic differentiation for complex model architectures. Adopting these improvements quickly provides competitive advantages, but framework updates risk breaking production training pipelines if dependencies conflict.
ABS provides tested upgrade paths for major framework releases, documenting compatibility with CUDA versions and verifying that existing model code continues to work. Updates are distributed through validated package repositories with rollback capabilities, allowing users to test new versions in isolated environments before committing production workflows. This managed update process balances the need for current software with production stability requirements.
For users who need bleeding-edge capabilities, ABS workstations support parallel framework installations through Python virtual environments or conda, enabling experimentation with pre-release versions without compromising stable environments. The professional-grade memory configurations in ABS systems provide sufficient capacity to maintain multiple complete development environments simultaneously.
 Model Deployment: From Training to Inference
Model Deployment: From Training to Inference
AI workflows don’t stop at training. Deploying models for production inference requires additional software infrastructure: ONNX Runtime for cross-framework model export, TensorRT for optimized inference on NVIDIA GPUs, and Triton Inference Server for model serving at scale. ABS workstations include these deployment tools pre-configured, enabling seamless transitions from training to production.
Users can train a PyTorch model, export it to ONNX format, optimize it with TensorRT for inference acceleration, and benchmark serving throughput—all on the same workstation without managing separate deployment infrastructure. For projects where edge deployment is the goal, cross-compilation toolchains and ARM emulation environments allow testing inference performance before deploying to production hardware. This end-to-end workflow integration, supported by the software stack on ABS AI Workstations, reduces the typical friction between research and production deployment.
Support and Documentation: When You Need Help
Even well-integrated software environments occasionally require troubleshooting. ABS provides technical support from engineers familiar with AI workloads and deep learning frameworks, offering expertise that generic IT support cannot match. When a CUDA out-of-memory error occurs during multi-GPU training or a model checkpoint fails to load after a framework update, ABS support can identify whether the issue stems from hardware, driver, framework, or model code—accelerating resolution compared to searching forums or filing GitHub issues.
Documentation accompanies every workstation, covering common workflows like setting up distributed training, configuring TensorBoard for remote access, optimizing data loading pipelines, and managing multiple Python environments. For organizations onboarding new team members, this documentation reduces training time and helps junior engineers become productive quickly. The ABS Zaurion Pro includes advanced setup guides for multi-GPU configurations and network-attached storage integration, addressing the specific needs of professional AI development teams.
Ready to Start: No Excuses, Just Results
The difference between an ABS AI Workstation and a custom build extends far beyond hardware specifications. The integrated, tested, and supported software environment transforms an expensive collection of components into a productive AI development platform that works from day one. For professionals whose time is better spent developing models than debugging driver conflicts, ABS AI Workstations deliver the software integration advantages that make local AI development practical, efficient, and frustration-free.